Die Sportec Solutions GmbH ist ein Joint Venture zwischen Deltatre und der DFL Gruppe mit Sitz in München und entwickelt zukunftsweisende Lösungen in den Bereichen der Spieldaten und Sporttechnologien.
Note: a English translation of this page can be found here
Hintergrund
Anfang 2021 wurde ich von der Sportec Solutions beauftragt einen neuen Service zur automatisierten Erstellung von sogenannten “Autotexten” zu entwickeln.
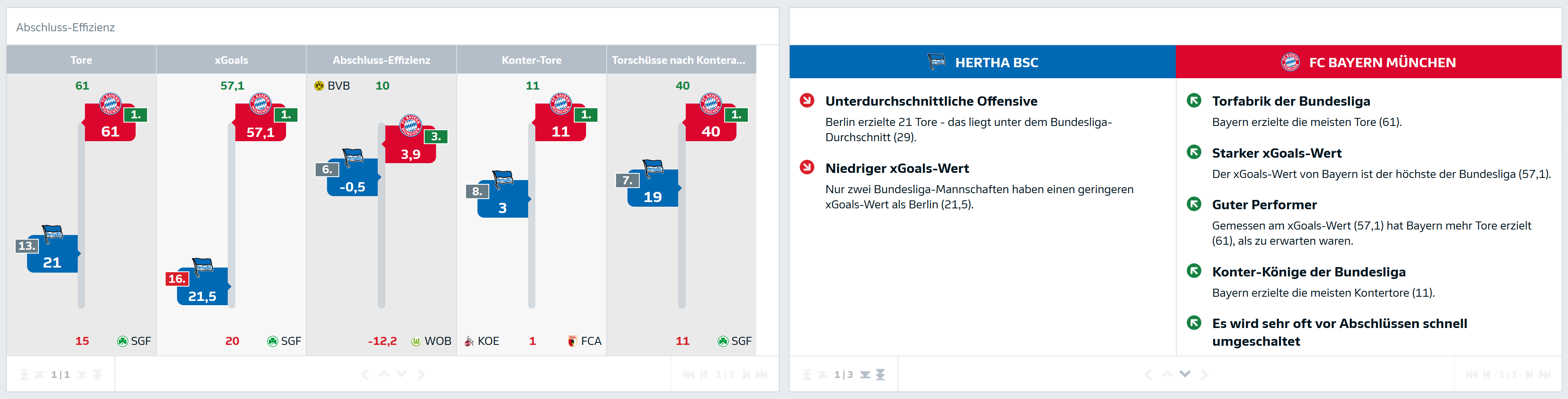
Die generierten Texte sollen unter anderem für die Bundesliga im “Match Analysis Hub” angezeigt werden. Der “Match Analysis Hub” stellt über eine Webanwendung ein Online-Dashboard aller relevanten Statistiken der Fußballvereine aller Bundesligen dar und wird u.a. von Redakteuren oder auch von Mitarbeitern der jeweiligen Vereine zur Analyse und Auswertung herangezogen.
Um zu den visuellen Darstellungen der Statistiken (wie z.B. Torschüsse, Flanken, Fouls, u.v.m) passend formulierte Texte zu platzieren, soll hierzu eine Text Engine entwickelt werden, die der Redaktion folgende Möglichkeiten gibt:
- Template basierte Definition von Texten mit entsprechenden Platzhaltern:
- Statistikwert(e)
- Vereinsnamen
- Liga bzw. Wettbewerb
- Dynamisch zur Laufzeit berechnete Variablen
- Arithmetische Operationen (Addition, Subtraktion, Multiplikation, Division)
- Definition von Konditionen um zu bestimmen, unter welchen Umständen ein Text generiert werden darf
- Mehrsprachigkeit (Deutsch, Englisch, Spanisch)
- Gliederung der Texte in sogenannten Regelsätzen
- Ein Regelsatz kann eine oder mehrere Statistiken abrufen und Textdefinitionen fachlich gruppieren (z.B. alle relevanten Torschusstexte)
Die Text Engine soll in Echtzeit alle benötigten Statistikdaten aggregieren, auswerten und unter Beachtung aller Konditionen den oder die entsprechenden Texte generieren und ausliefern.
Als Ausgangspunkt wird ein bestimmter Wettbewerb (z.B. 2. Bundesliga 2020/2021), ein oder mehrere Vereine und der gewünschte Regelsatzname selektiert und an die Text Engine übertragen.
Die Kommunikation soll über eine HTTP API stattfinden.
Vorbereitung
In Absprache mit dem Kunden wurden alle Anforderungen zusammengestellt. Enger Austausch fand insbesondere mit der Redaktionsleitung statt, welche für die endgültige Definition aller Texte zuständig ist.
Nach der Vorstellung eines von mir entwickelten Prototypen (Proof of Concept) wurde das weitere Vorgehen abgestimmt und erste Arbeitspakete als User Stories in einem Kanban Board definiert.
In regelmäßig stattfindenden Besprechungen soll der aktuelle Stand der Entwicklung kommuniziert werden.
Umsetzung
Die Anwendung wurde von Anfang an in verschiedene Teilkomponenten gegliedert. Nennenswert sind hierfür die Applikationsschicht, die Implementierung des Templates und letztendlich die API.
Hintergrund ist eine gewisse Flexibilität um zukünftig jede Komponente durch eine andere Implementierung austauschbar bzw. einfach erweiterbar zu halten.
Die gesamte Anwendung wurde auf Basis von .NET 5 mit C# entwickelt und umgesetzt. Zur Qualitätssicherung wurden sowohl Unit als auch Integration Tests verfasst.
Template
Das Templating wurde mit Hilfe von XML umgesetzt. Der Vorteil liegt hier in einer relativ einfachen Lesbarkeit der zu erstellenden Regelsätze und deren Bestandteile. Über ein eigens definiertes Schema (XSD) wird die Struktur des XML-Dokuments festgelegt und dient dem Autor ebenfalls als Hilfestellung.
XML ist ein weit verbreiteter Standard zur Formulierung von strukturierten Daten und lässt sich in vielen gängigen Editoren einfach bearbeiten.
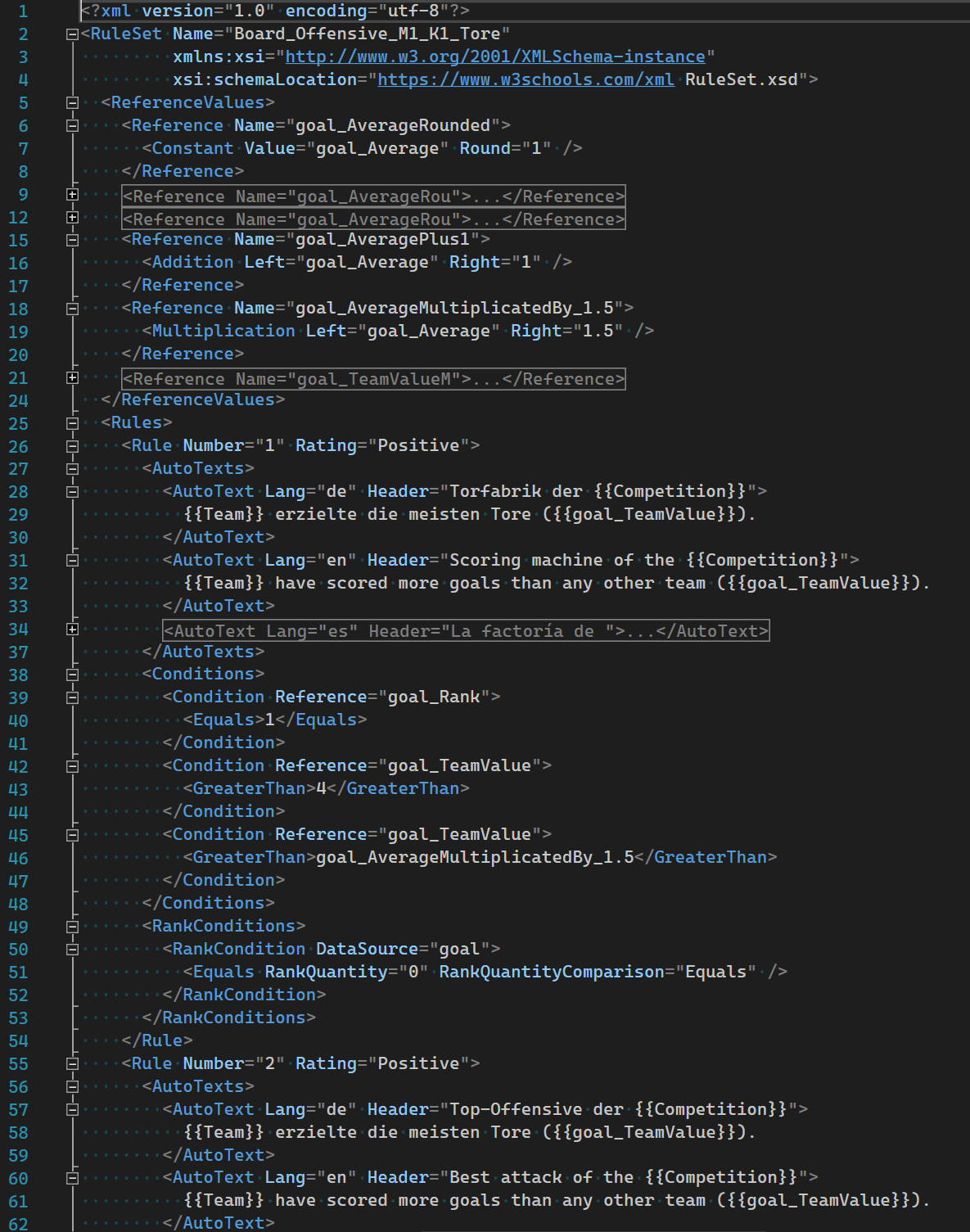
Falls nötig, kann zukünftig auch ein anderes Format (z.B. JSON) genutzt werden um Regelsätze als Template abzubilden.
Applikation
Die eigentliche Applikationslogik ist dafür zuständig alle nötigen Bestandteile des Textverabreitungsprozesses zu sammeln und durchzuführen.
Über die Anbindung interner HTTP APIs beschafft sich die Text Engine folgende Daten:
- Wettbewerbsinformationen
- Vereins- bzw. Teamdaten
- Statistikdaten
Ebenfalls wird der gewünschte Regelsatz in Form einer XML-Datei eingelesen und in Kombinationen mit den Daten für jedes angefragte Fußballteam ausgewertet.
Zur Auswertung zählen die dynamische Aufbereitung aller definierten Variablen, Ausführung der Konditionen und letztendlich die finale Selektion aller Treffer.
Jeder Treffer wird daraufhin mit Hilfe eines Textprozessors verarbeitet. Damit wird der Text in der angeforderten Lokalisation ausgewählt und Platzhalter mit den entsprechenden Werten ersetzt.
Die Treffer werden daraufhin als Auflistung von Autotexten bereitgestellt.
API
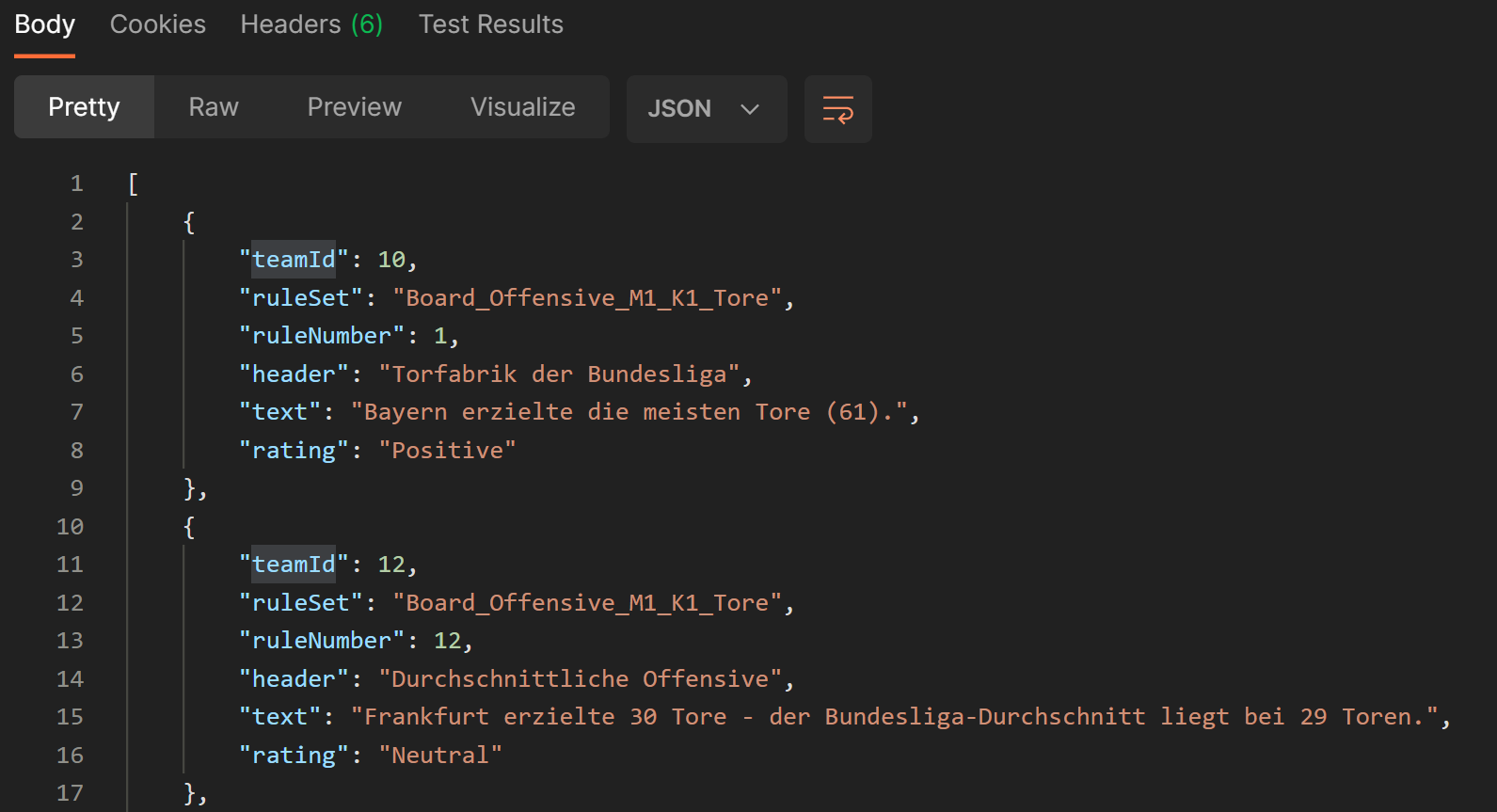
Die Dienste des “Match Analysis Hub” greifen über HTTP auf die ASP.NET API zu. Die API bietet hierbei mehrere Endpunkte an, um einen oder direkt mehrere Regelsätze an Autotexten abzufragen.
Gesichert wurde die API mit HTTP über TLS (HTTPS). Ebenso ist eine OAuth-Authentifizierung mit Bearer Token nötig.
Die berechneten Autotexte werden im Body der HTTP Response im JSON-Format an den Aufrufer zurückgegeben.
Zur Dokumentation und dem vereinfachten Testen der API wurde eine OpenAPI-Dokumentation und eine Postman-Collection angelegt.
Technologien
Im Gesamtkontext nutzt die Text Engine u.a. die folgenden Technologien:
- .NET 5
- C#
- ASP.NET
- HTTP
- XML
- JSON
- OAuth
- OpenID Connect
- Swagger (OpenAPI)
- Fluid
- Serilog
- xUnit
- Benchmark.NET
- Docker
Performance
Vom Kunden wurde stets betont, dass die Anwendung die Autotexte möglichst schnell berechnen und ausgeben soll. Um dem Nutzer des “Match Analaysis Hub” eine zufriedenstellende Erfahrung sicherzustellen ist eine schnell reagierende Webanwendung ein entsprechend wichtiger Bestandteil. Dazu gehören ebenso die Hintergrunddienste, zu dem die Text Engine API ebenfalls zählt.
Zur stetigen Messung der Laufzeit zur Berechnung eines typischen Regelsatzes wurden regelmäßig Benchmarks ausgeführt. Auf den Entwicklungsmaschinen betrug diese im Schnitt lediglich ca. 160 µs (Mikrosekunden).
Im produktiven Umfeld erhält das “Match Analysis Hub” Backend die angefragten Textbausteine von der Text Engine API innerhalb von durchschnittlich 4-8 ms.
Betrieb
Die Text Engine API wurde automatisiert als Docker Image in ein Kubernetes Cluster von AWS deployed. Updates und Weiterentwicklungen können auf diesem Wege ebenfalls rasch ausgeliefert werden.
Monitoring
Um den Betrieb sicherzustellen und das Verhalten der Anwendung nachvollziehbar zu machen werden entsprechende Logs an einen ELK-Stack (Elasticsearch und Kibana) gesendet.
Ebenfalls werden typische Metriken (CPU, Speicherauslastung, .NET Garbage Collection, HTTP Requests/Sekunde, u.a.) über Prometheus abgefragt und per Grafana Instanz visualisiert.
Fazit
Die Anforderungen des Kunden wurden zur vollsten Zufriedenheit erfüllt. Seit der jüngsten Veröffentlichung des “Match Analysis Hub” sind die generierten Texte sowohl für die Bundesligen als auch für den DFB-Pokal für alle Nutzer sichtbar und reichern die Inhalte somit redaktionell als auch visuell an.
Ausblick
Für die zukünftige Entwicklung wird in Betracht gezogen einen WYSIWYG Editor bereitzustellen, der es den redaktionellen Mitarbeitern ermöglicht, die Bestandteile eines Regelsatzes einfach visuell zu gestalten, anstatt das endgültige XML-Dokument per Hand zu bearbeiten.
Ferner wäre es auch möglich die grundlegenden Funktionalität der Text Engine für Ticker-Texte oder andere redaktionelle Inhalte zu verwenden bzw. zu erweitern.