Sportec Solutions GmbH is a joint venture between Deltatre and the DFL Group based in Munich and develops forward-looking solutions in the fields of match data and sports technologies.
Hinweis: eine deutsche Übersetzung dieser Seite befindet sich hier
Background
At the beginning of 2021, I was commissioned by Sportec Solutions to develop a new service for the automated generation of so-called “auto texts”.
The generated texts are to be displayed in the “Match Analysis Hub” for the Bundesliga, among others. The “Match Analysis Hub” provides an online dashboard of all relevant statistics of the soccer clubs of all German leagues via a web application and is used, among others, by editors or also by employees of the respective clubs for analysis and evaluation.
In order to place appropriately formulated texts to the visual representations of the statistics (such as shots on goal, crosses, fouls, etc.), a text engine is to be developed for this purpose, which will give the editors the following options:
- Template-based definition of texts with corresponding placeholders:
- Statistical values
- Club names
- League / competition
- Variables dynamically calculated at runtime
- Arithmetic operations (addition, subtraction, multiplication, division)
- Definition of conditions to determine under which circumstances a text may be generated
- Multilingual (German, English, Spanish)
- Structuring of texts in so-called rule sets
- A rule set can retrieve one or more statistics and group text definitions by subject (e.g. all relevant goal shot texts)
The Text Engine is to aggregate and evaluate all required statistical data in real time and generate and deliver the corresponding text(s) in compliance with all conditions.
As a starting point, a specific competition (e.g. 2nd Bundesliga 2020/2021), one or more clubs and the desired rule set name are selected and transferred to the Text Engine.
The communication is to take place via an HTTP API.
Preparation
All requirements were compiled in consultation with the customer. Close exchange took place in particular with the editorial management, which is responsible for the final definition of all texts.
After the presentation of a prototype (proof of concept) developed by me, the further procedure was coordinated and first work packages were defined as user stories in a Kanban board.
The current state of development will be communicated in regular meetings.
Implementation
The application was divided into various subcomponents from the very beginning. Worth mentioning are the application layer, the implementation of the template and finally the API.
The background is a certain flexibility to keep each component replaceable by another implementation or easily extendable in the future.
The entire application was developed and implemented on the basis of .NET 5 with C#. For quality assurance both unit and integration tests were written.
Template
The templating was implemented with the help of XML. The advantage here is the relatively simple readability of the rule sets to be created. The structure of the XML document is specified via a specially defined schema (XSD) and also serves as an assistance for the author.
XML is a widely used standard for formulating structured data and can be easily edited in many common editors.
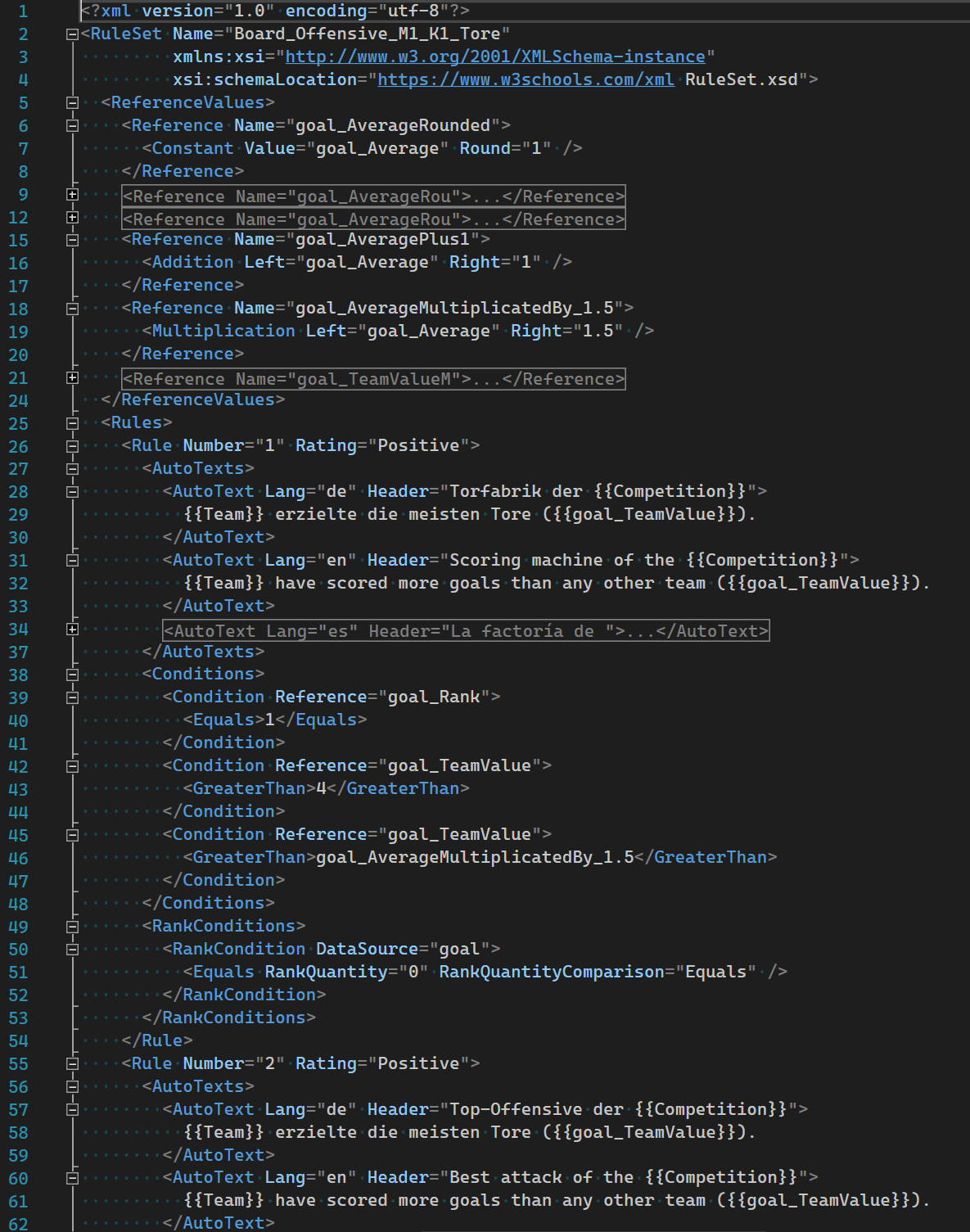
If necessary, another format (e.g. JSON) can be used in the future to map rule sets as templates.
Application
The actual application logic is responsible for collecting and executing all necessary components of the text distribution process.
Through the connection of internal HTTP APIs, the text engine obtains the following data:
- Competition information
- Clubs / teams data
- Statistical data
Likewise, the desired rule set is read in as an XML file and evaluated in combination with the data for each requested soccer team.
The evaluation includes the dynamic preparation of all defined variables, execution of the conditions and finally the final selection of all hits.
Each hit is then processed using a text processor. This selects the text in the requested localization and replaces placeholders with the appropriate values.
The hits are then provided as a list of auto texts.
API
The services of the “Match Analysis Hub” access the ASP.NET API via HTTP. The API offers several endpoints to query one or more rule sets of auto texts directly.
The API is secured with HTTP over TLS (HTTPS). OAuth authentication with bearer tokens is also required.
The computed auto texts are returned to the caller in the body of the HTTP response in JSON format.
For documentation and simplified testing of the API, OpenAPI documentation and a Postman collection have been created.
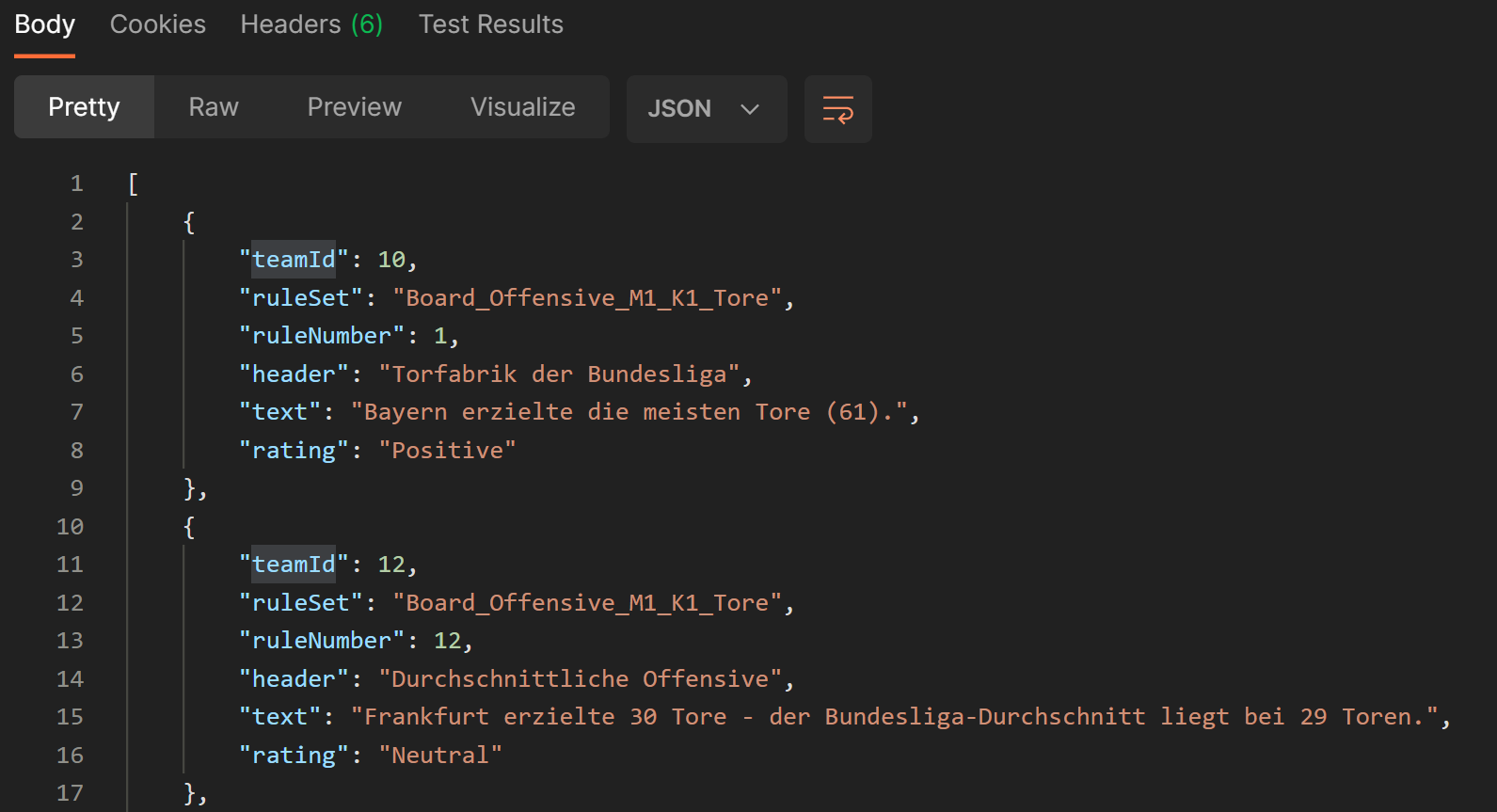
Technologies
In the overall context, the Text Engine uses the following technologies, among others:
- .NET 5
- C#
- ASP.NET
- HTTP
- XML
- JSON
- OAuth
- OpenID Connect
- Swagger (OpenAPI)
- Fluid
- Serilog
- xUnit
- Benchmark.NET
- Docker
Performance
It was always emphasized by the customer that the application should calculate and output the auto texts as quickly as possible. In order to ensure a satisfactory experience for the user of the “Match Analaysis Hub”, a fast responding web application is a correspondingly important component. This also includes the background services, to which the Text Engine API also belongs.
To constantly measure the runtime for calculating a typical rule set, benchmarks were regularly run. On the development machines, this averaged only about 160 µs (microseconds).
In the productive environment, the “Match Analysis Hub” backend receives the requested text modules from the Text Engine API within an average of 4-8 ms.
Operating
The Text Engine API was automatically deployed as a Docker image to a Kubernetes cluster on AWS. Updates and further developments can also be delivered quickly that way.
Monitoring
In order to ensure operation and to make the behavior of the application traceable, corresponding logs are sent to an ELK stack (Elasticsearch and Kibana).
Also typical metrics (CPU, memory usage, .NET garbage collection, HTTP requests/second, etc.) are queried via Prometheus and visualized via a Grafana instance.
Summary
The customer’s requirements were met to their complete satisfaction. Since the recent release of the “Match Analysis Hub”, the generated texts for both the Bundesligen and the DFB-Pokal are visible to all users, thus enriching the content editorially as well as visually.
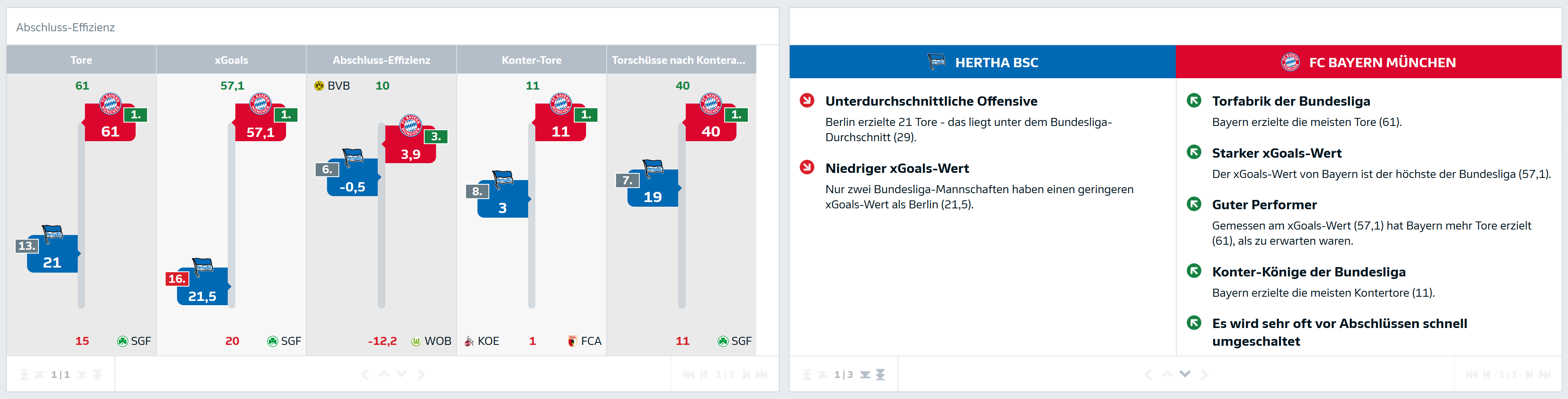
Outlook
For future development, it is being considered to provide a WYSIWYG editor that would allow editorial staff to easily design the components of a rule set visually instead of editing the final XML document by hand.
Furthermore, it would also be possible to use or extend the basic functionality of the Text Engine for ticker texts or other editorial content.